|
Možnosti používat v těle i v hlavičce zpráv jiné než čisté ASCII znaky, stejně tak jako možnosti přikládat ke zprávám nejrůznější přílohy převážně netextového charakteru, stojí v cestě pouze sedmibitový (garantovaný) charakter přenosového mechanismu, daný použitým protokolem SMTP. Standard MIME proto musí definovat způsob, jakým osmibitové znaky (resp. osmibitové byty) převést před přenosem na znaky sedmibitové, a po přenosu je zase vrátit zpět do původní podoby. Jde vlastně o potřebu definovat vhodný způsob kódování (anglicky: encoding).
MIME definuje dokonce dva takovéto způsoby kódování, označované jako "quoted-printable" a "Base64", ale nepředepisuje striktně který má být kdy použit. Pouze doporučuje použití kódování "quoted printable" tam, kde se výchozí text příliš neodlišuje od čistého ASCII textu (tj. neobsahuje příliš mnoho "cizorodých" znaků), a alternativní kódování Base64 tam, kde je odlišnost od čistého ASCII textu větší. Logika, ze které toto doporučení vychází, je dána konkrétní povahou obou způsobů kódování:
- Kódování "quoted-printable" ponechává čisté ASCII znaky (tj. znaky znázornitelné v 7 bitech) tak jak jsou, a kóduje pouze ostatní znaky. To činí takovým způsobem, že číselný kód osmibitového znaku vyjádří jako dvojici hexadecimálních číslic (psaných velkými písmeny), a pro potřebné odlišení od původních ASCII znaků je uvodí jedním rovnítkem. Každý "osmibitový" znak tak vlastně nahradí trojicí sedmibitových znaků, například naše "Č", které má ve znakové sadě ISO-8859-2 kód C8 (hexadecimálně), nahradí trojicí znaků "=C8" apod., a mezeru nahradí podtržítkem. Například slůvko "Článek" je pak v tomto kódování reprezentováno řetězcem "=C8l=E1nek". Při troše cviku (a malé četnosti diakritiky) je zakódovaný tvar pro člověka stále srozumitelný. Při větší četnosti jiných než čistých ASCII znaků však roste neefektivnost tohoto způsobu kódování.
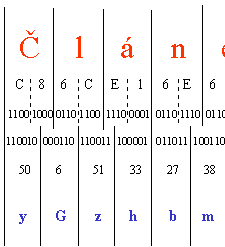 |
Představa kódování Base64
Kódování Base64 generuje vždy stejně dlouhé znakové řetězce ze sedmibitových znaků, bez ohledu na to, jaká je četnost ne-ASCII znaků v původním textu. Pro názornost si lze představit, že v tomto kódování se vezmou binární hodnoty všech znaků, seřadí se za sebou do jednoho souvislého bitového řetězce, a následně se z něj "vykrojí" šestice po sobě jdoucích bitů. Tyto šestice lze chápat také jako čísla od 0 do 63, a použijí se jako indexy do pevně dané kódovací tabulky. V té se nachází znaky (samozřejmě čisté ASCII znaky), které nahradí původní šestici bitů ve výsledném kódu, který je následně přenášen. Celou představu ukazuje obrázek. Pro srovnání: zdrojový řetězec "Článek" je v kódování Base64 nahražen řetězcem "yGzhbmVrI", který snad dostatečně názorně dokumentuje skutečnost, že tento způsob kódování je pro člověka zcela nesrozumitelný.
|


