|
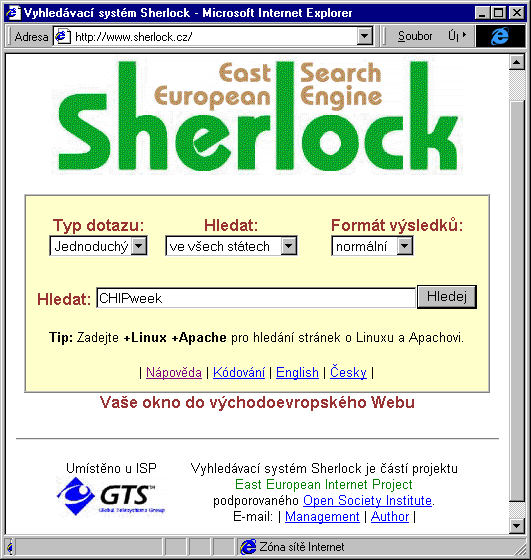
Domovská stránka s vyhledávacím formulářem
V nedávných dnech byla veřejnosti zpřístupněna další vyhledávací služba, která hodlá nabízet plnotextové vyhledávání v českém a slovenském Internetu. Je tedy v pořadí již čtvrtou - po Atlasu, Kompasu a službě Search CZ - ale kupodivu není nejmladší. Jde totiž zřejmě o určitou "reinkarnaci" jednoho dřívějšího projektu, který nesl stejné jméno jako nyní zprovozněná služba: Sherlock.
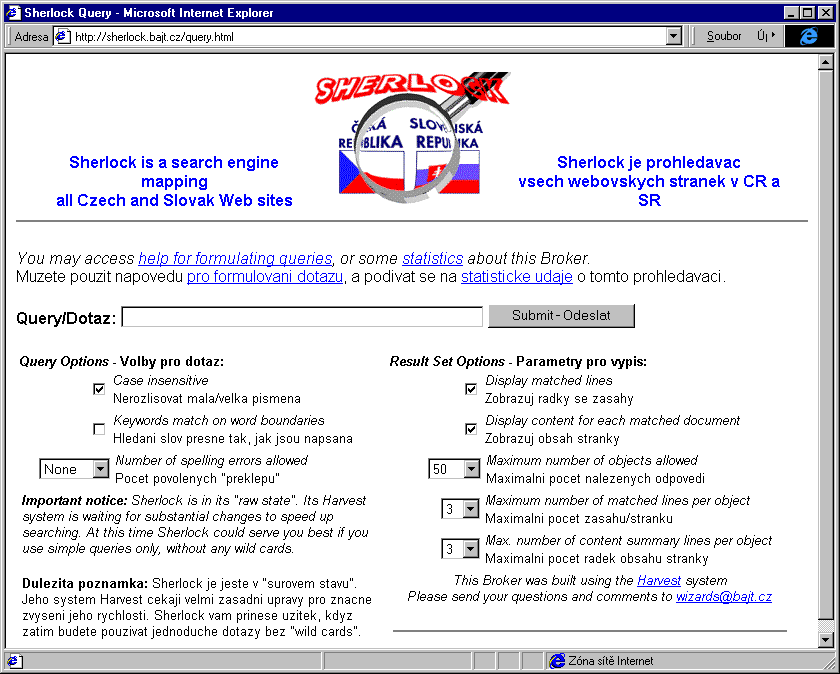
Za původním projektem vyhledávací služby Sherlock stál pan Zajíček z firmy Bajt (dříve vydavatel stejnojmenného tištěného časopisu), a tato jeho původní služba je dodnes nabízena na stránkách WWW serveru Bajtu (na adrese http://sherlock.bajt.cz, viz třetí obrázek). Nepamatuji se již na dobu, kdy fungovala (dnes vrací pouze chybovou hlášku), ale dobře si pamatuji na způsob, jakým tehdy lidé z Bajtu "sbírali" data a mapovali český Internet. Dělali to tak, že se podívali do systému DNS na to, jaké kde existují počítače, a pak každý z nich zkoušeli oslovit na portu číslo 80 (na kterém je standardně umístěn WWW server - tím totiž zjišťovali, zda příslušný počítač je či není WWW serverem, a pokud ano, snažili se načíst jeho obsah). Byl to způsob asi stejně kultivovaný a druhou stranou vítaný, jako když vám někdo systematicky obchází všechny dveře, bere za jejich kliky a zkouší, jestli náhodou není otevřeno. Jak měl potom správce "navštívené" sítě poznat, že nejde o útok hackera, který si mapuje terén? Slušně vychované vyhledávací služby se takto nechovají, a o nových zdrojích se dozvídají jednak z hypertextových odkazů vedoucích z již prozkoumaných stránek, nebo tím způsobem, že nabízí zřizovatelům nových stránek, aby je explicitně upozornili na své stránky (aby si je u příslušné vyhledávací služby tzv. zaregistrovali - k čemuž stačí pouhé sdělení příslušného URL odkazu na jednu z nových stránek, načež vyhledávací služba si již sama "rozleze" celou soustavu nových stránek a zmapuje si jejich obsah). U nové verze služby Sherlock jsem však takovouto možnost vlastního zadání URL odkazu nenašel.
 |
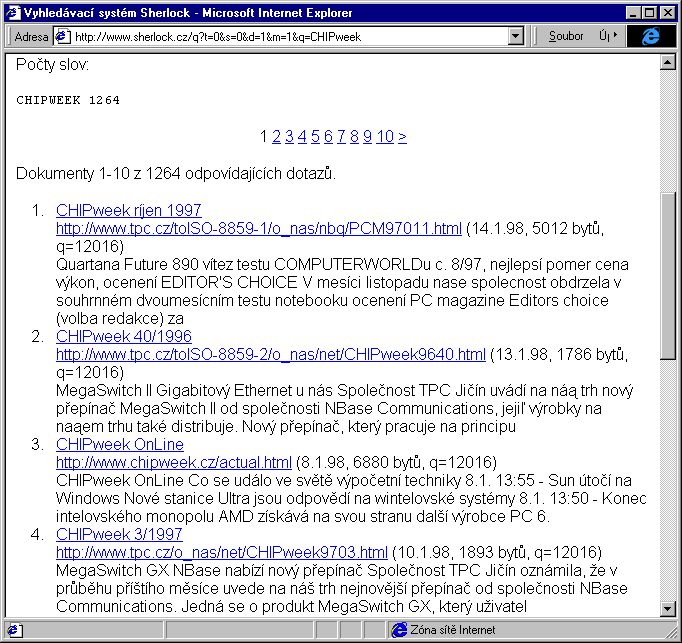
Příklad výsledků
|
|
Nová verze vyhledávací služby Sherlock sídlí v samostatné doméně (www.sherlock.cz), a o její vazbě na původního Sherlocka kromě stejného jména svědčí vlastně jen to, že je pod ní podepsán (jako manažer) opět pan Ladislav Zajíček, z firmy Bajt. Autory technického řešení nového Sherlocka jsou dva studenti pražské Matematicko-fyzikální fakulty, a peníze na celý projekt zřejmě poskytla nadace pana Sörose (viz spodní část prvního obrázku). Pokud jde o technické řešení, to je zcela původní (z autorské dílny obou studentů MFF UK), a nabízí některé věci, které jiné vyhledávací služby nemají: například možnost přidělit jednotlivým hledaným klíčovým slovům různé váhy, a tím šikovně uzpůsobit vyhledávání svým specifickým potřebám. Další perličkou je možnost vyspecifikovat přímo v dotazu, že si chcete nechat zobrazit přímo n-tou stránku s výpisy výsledků - což sice odstraňuje pracné proklikávání se mnoha výsledkovými stránkami, ale na druhé straně mi poněkud uniká smysl toho, že mám možnost přeskočit nejlepší výsledky, a zajímat se jen o ty, které méně dobře odpovídají mému dotazu. Nenašel jsem ani možnost vyhledávání frází, a zejména mne zaujala neexistence jakékoli zmínky o diakritice - když jde o původní český produkt, měli autoři možnost se vyrovnat s češtinou tak, jak považovali za vhodné. Empiricky jsem si vyzkoušel, že dotazy s diakritikou zadávat lze, a výsledkem jsou stránky s příslušnými klíčovými slovy včetně diakritiky - ovšem jen v té samé diakritice, v jaké byl dotaz položen. Zřejmě tedy celý systém vyhledávání diakritiku nijak neinterpretuje, a každý znak hledá "tak jak stojí a leží". V důsledku toho pak může být dosti zkreslený údaj o počtu nalezených stránek, protože různé jazykové mutace pak jsou počítány jako samostatné (navzájem odlišné) stránky.
 |
Původní Sherlock je stále ještě dostupný (i když nefunkční)
|